Taking Arms Against A Sea of Objects
Preface
I’ve recently been learning Rust, so I added a new Rust tag to keep notes related to it.
This is the first post under that tag. It mainly introduces Rust’s concepts of ownership and references. As for the meaning of the title, let’s leave that as a cliffhanger for now — we’ll come back to it at the end.
Systems Programming Languages
Let’s start with a quick introduction to Rust.
Rust is a systems programming language targeting the same space as C++, but without C++’s historical baggage.
So what exactly is systems programming? To answer that, it’s helpful to contrast it with application programming. The key difference is that application programming builds software that directly serves end‑users, whereas systems programming builds software that serves other software. I work as an iOS developer, which falls into the application programming category.
Typical examples of systems programming include operating systems, file systems, device drivers, databases, and audio/video codecs. From these examples, we can see that systems programming is essentially programming in resource‑constrained environments, where every byte of memory and every CPU cycle matters.
Memory Management
When we talk about memory management, we generally want a language to offer two properties:
- Control
- Safety
Control
Consider this C++ example:
int main() {
std::string s = "Hello World";
}
On line 2, we create a string variable s on the stack. Its memory layout looks roughly like this:
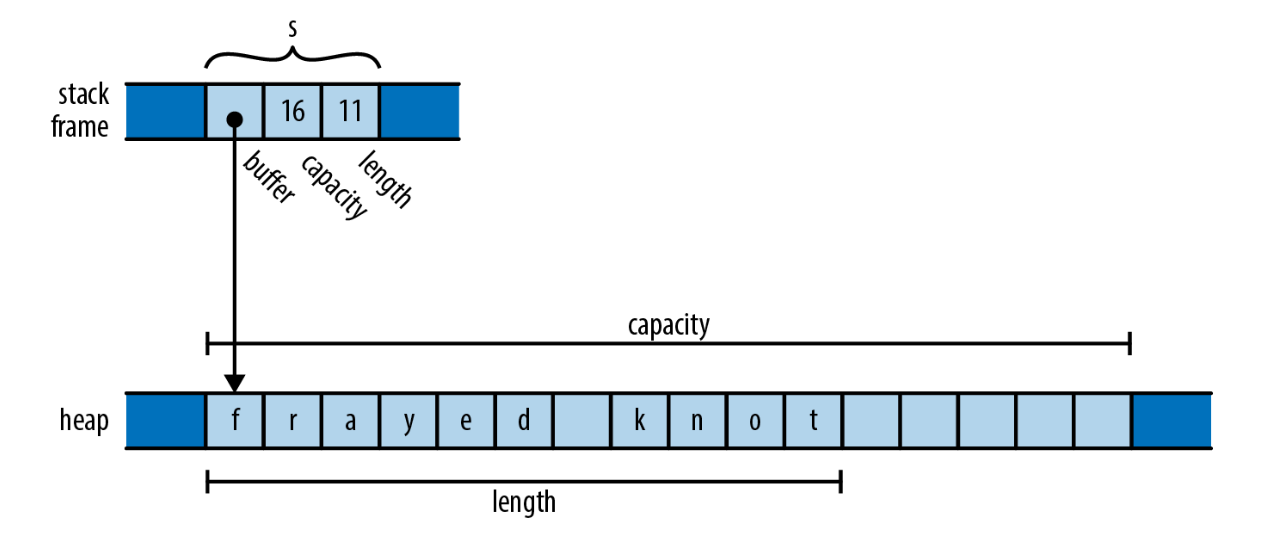
When execution reaches line 3 and s goes out of scope, the memory shown above is automatically freed.
Control here means that we, as programmers, decide when memory is freed.
Safety
Let’s look at another C++ example:
int main() {
std::vector<int> v = {1};
auto& elem = v[0];
v.push_back(2);
cout << elem;
}
On line 2 we initialize a std::vector<int> v with a single element 1, and on line 3 we create a reference elem to the first element of the vector. The memory looks roughly like this:
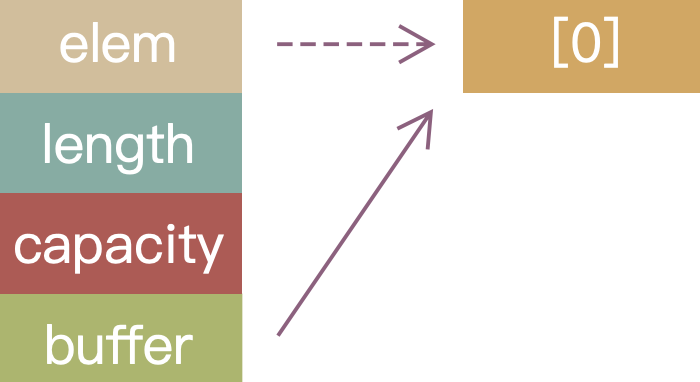
On line 4 we push a new element 2 onto the end of the vector. Since the current buffer is too small, the vector reallocates a larger chunk of memory and copies the existing elements into it. The old memory region is now invalid:
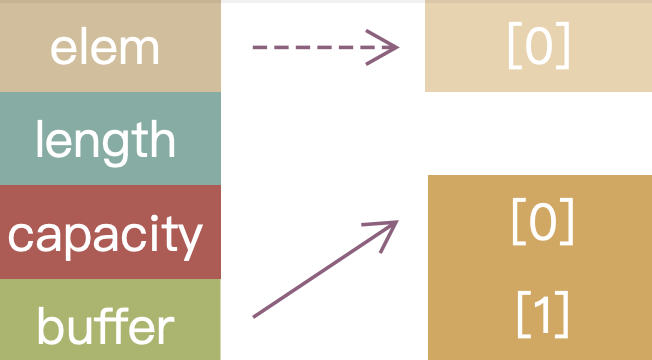
As shown above, the buffer now points to the new memory region, while elem still points to the old, now‑invalid memory (grayed‑out in the diagram). elem has become a dangling reference.
Safety means we can only access memory safely. In this example, we should no longer be able to access memory via elem. Continuing to use it leads to undefined behavior, crashes, or even security vulnerabilities.
Control Or Safety
Control and safety sound almost mutually exclusive. If you can precisely control when memory is freed, it becomes harder to guarantee safety; and vice versa. As a result, most modern languages fall into two broad camps:
- One camp prioritizes safety, delegating memory management to a garbage collector (GC). The GC tracks and cleans up unused memory on behalf of the programmer. This approach requires a runtime and still cannot fully avoid issues like iterator invalidation or data races. Most modern languages — Swift, Go, Ruby, Python, etc. — fall into this camp.
- The other camp prioritizes control and gives programmers direct responsibility for memory management. They must identify unused memory and explicitly free it at the right time. Getting this right is hard:
- Forgetting to free memory leads to leaks.
- Freeing memory too early leads to dangling references.
- Freeing the same memory twice leads to double frees.
Among today’s mainstream languages, only C and C++ live in this camp.
When faced with this apparent either–or choice, Rust gives a very different answer: “Only children make choices. I want both.” So how does Rust provide both strong control and strong safety? That’s what we’ll look at next.
Ownership
Rust uses a mechanism called ownership to manage memory. Ownership consists of a specific set of rules that allow the compiler to perform checks at compile time, with zero runtime overhead.
First, here are the rules of ownership:
- Every value in Rust has a variable that is called its owner.
- There can be only one owner at a time.
- When the owner goes out of scope, the value is dropped.
With the rules in hand, let’s start with a simple example:
fn main() {
let mut padovan = vec![1,1,1];
for i in 3..10 {
let next = padovan[i-3] + padovan[i-2];
padovan.push(next);
}
println!("P(1..10) = {:?}", padovan);
}
On line 2 we initialize a vector and assign it to padovan. At this point, padovan is the owner of that vector. When padovan goes out of scope at the end of main, the vector value is dropped.
Now let’s look at a slightly more complex example:
struct Person {
name: String,
birth: i32
}
fn main() {
let mut composers = Vec::new();
composers.push(Person { name: "Palestrina".to_string(), birth: 1525 });
composers.push(Person { name: "Dowland".to_string(), birth: 1563 });
composers.push(Person { name: "Lully".to_string(),birth: 1632 });
for composer in &composers {
println!("{}, born {}", composer.name, composer.birth);
}
}
Just as variables own their values, structs own their fields, and tuples/arrays own their elements. The memory diagram looks like this:
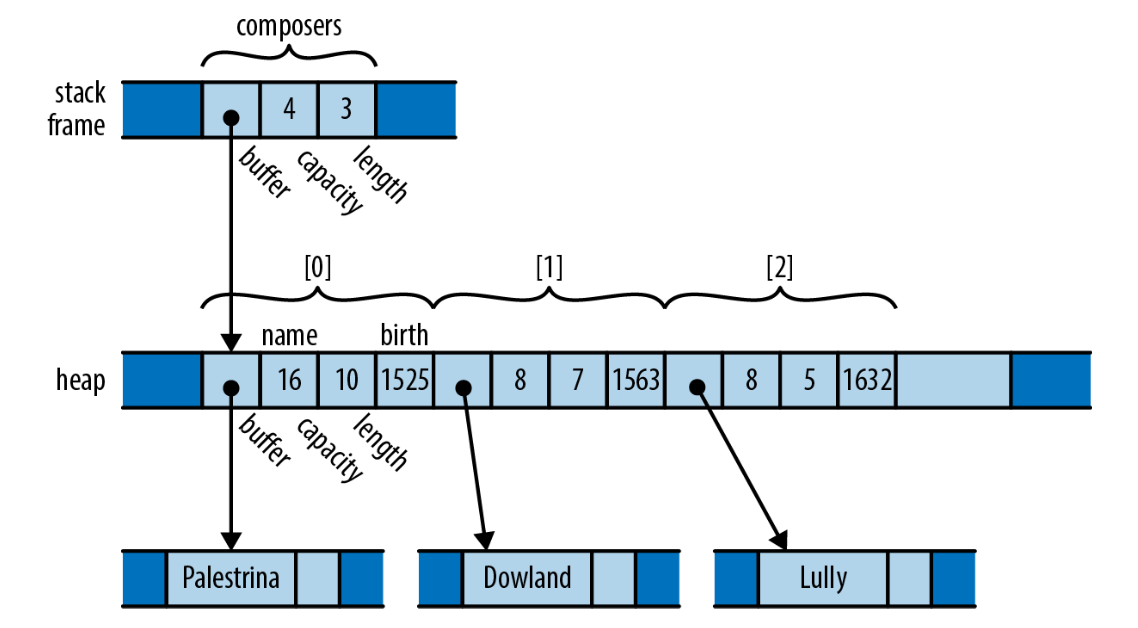
The ownership relationships in this example are numerous, but very straightforward: composers owns a vector, the vector owns several Persons, each Person owns its own fields, the name field owns the string buffer, and birth owns its integer. When composers goes out of scope, all of these resources are freed.
Note that while each value has exactly one owner, the reverse is not necessarily one‑to‑one. As in this example, a vector owns multiple Person values — a one‑to‑many relationship.
In some ways, ownership makes Rust feel less flexible than other languages, where you can freely build arbitrary object graphs and let objects reference each other in any direction you want. But:
- Precisely because the relationships are simpler, Rust can provide more powerful static analysis tools.
- Rust’s strong safety guarantees are made possible by these easier‑to‑track relationships.
- You can reason about the lifetime of values just by reading the code, without running it.
So far, ownership may not seem that useful. But Rust has additional strategies that extend it and make it far more flexible, which we’ll see next.
Moving Ownership
Unlike many other languages, in Rust assignment, passing arguments to functions, and returning values from functions do not necessarily mean copying. Instead, they usually mean moving ownership. After ownership is moved, the original owner becomes uninitialized and unusable. The compiler enforces this.
You might be surprised that Rust changes the semantics of something as basic as assignment. But if you look at how different languages handle assignment, you’ll see that the semantics already vary significantly.
Assignment in Python
s = ['udon', 'ramen', 'soba']
t = s
u = s
On line 1, we initialize s with a list of strings, and then assign s to t and u. The final memory diagram looks like this:
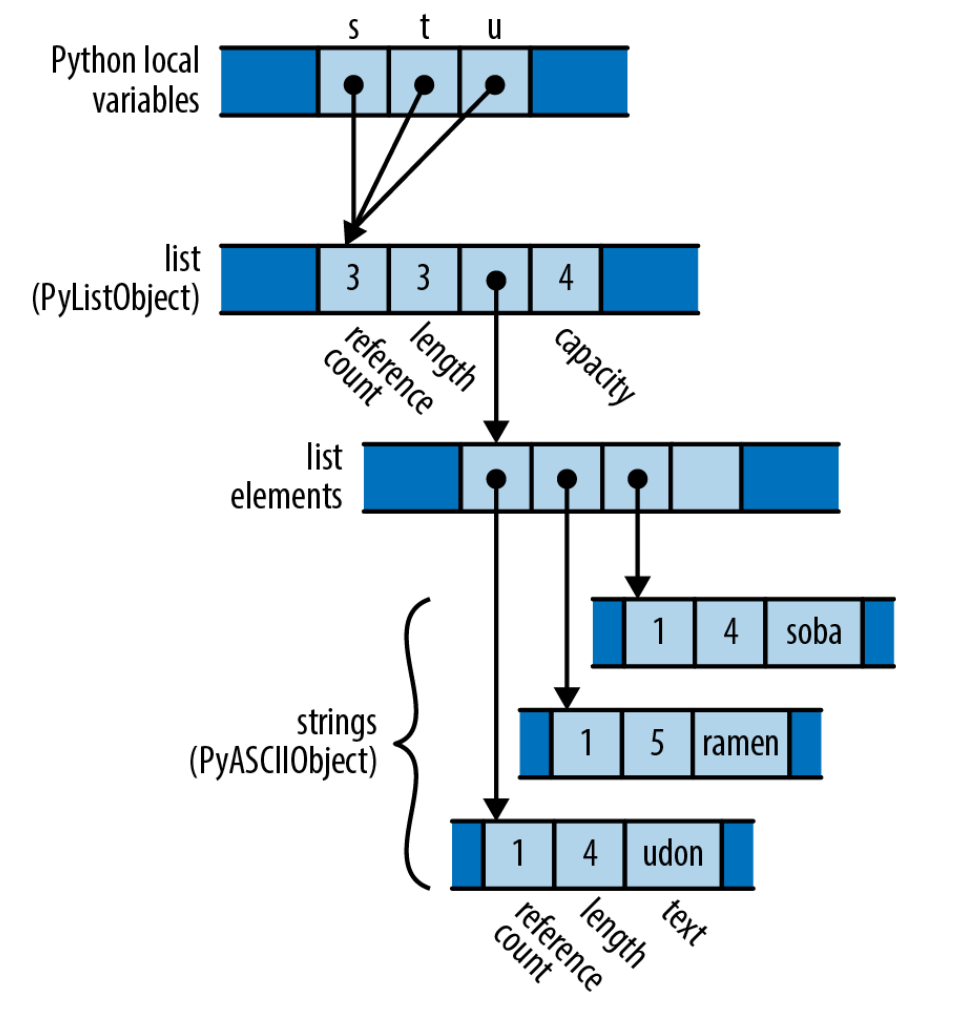
In Python, assignment just updates reference counts, so it’s a very cheap operation — at the cost of maintaining reference counts for every object.
Assignment in C++
std::vector<string> s = { "udon", "ramen", "soba" };
std::vector<string> t = s;
std::vector<string> u = s;
Using the same example in C++, assignment results in the following memory layout:
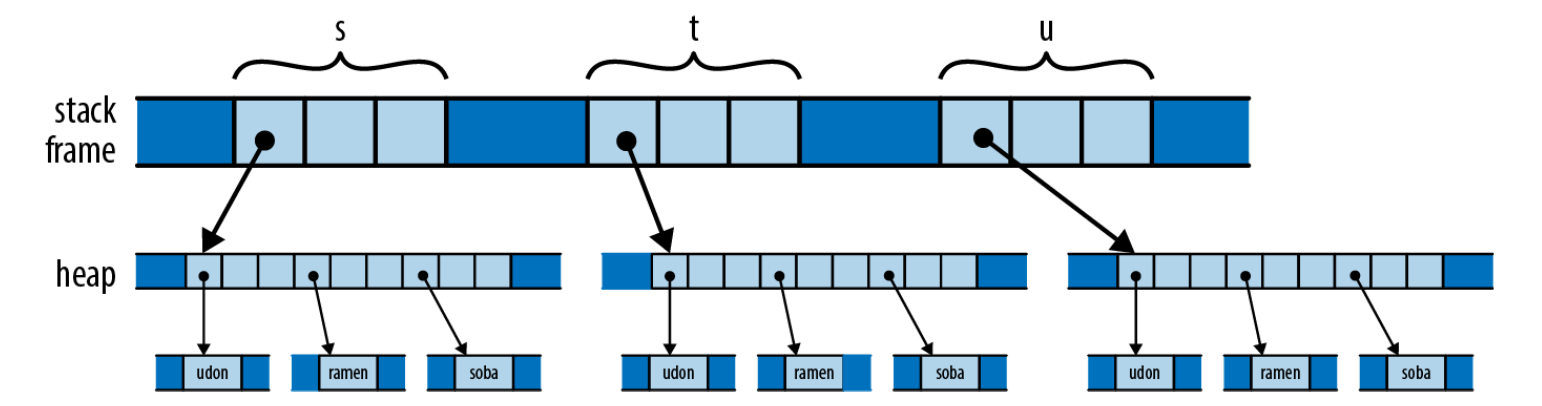
Here, assignment performs a deep copy. The memory and time costs depend on the types involved, but ownership is clear. (Note: this is just a didactic example; in real code you’d use more efficient techniques than repeated assignment.)
Assignment in Rust
Now let’s see what the same example looks like in Rust:
fn main() {
let s = vec!["udon".to_string(), "ramen".to_string(), "soba".to_string()];
let t = s;
let u = s;
}
After initializing s, the memory layout is roughly:
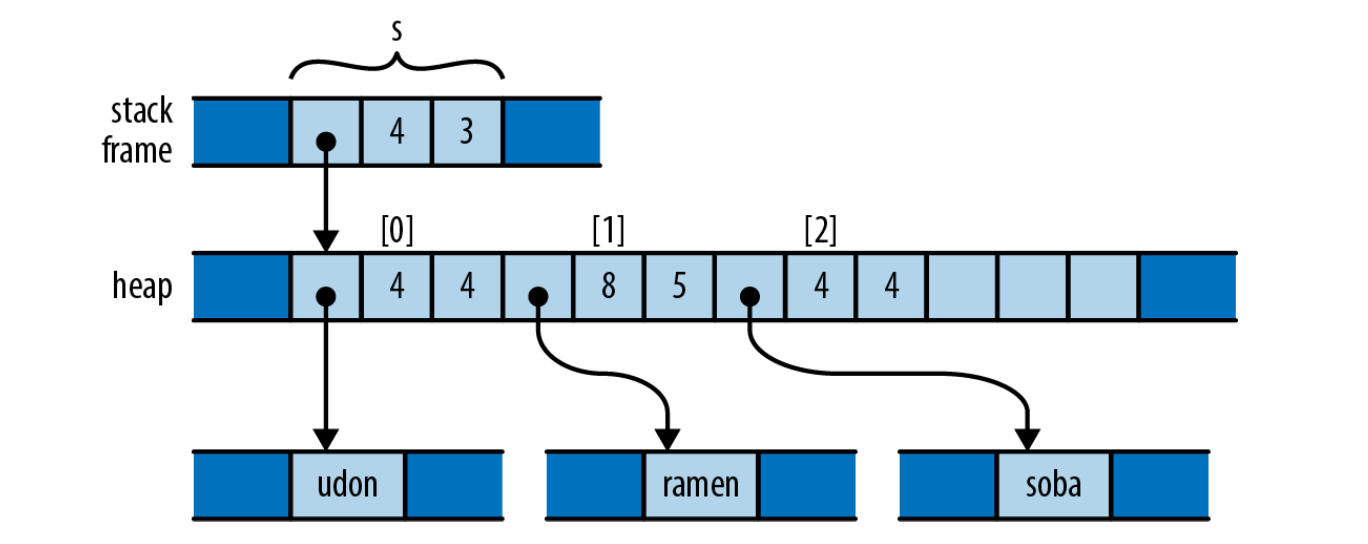
Then we assign s to t:
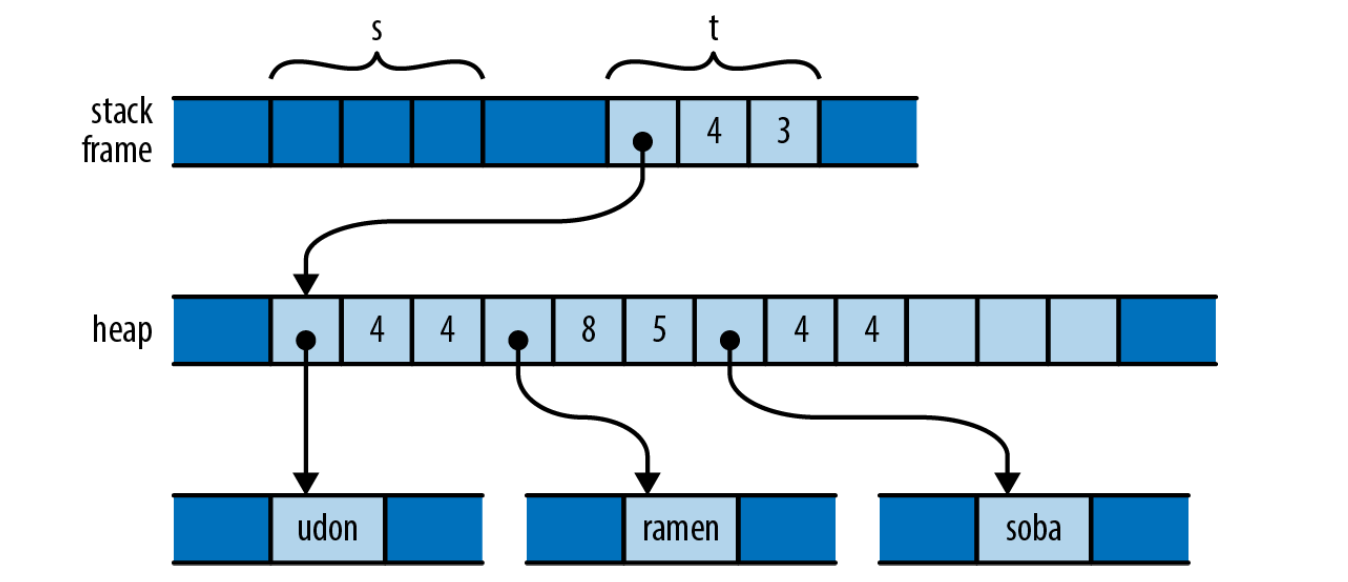
Ownership of the vector has moved from s to t. The vector elements and the three string buffers remain as they are; the vector still has exactly one owner. Observant readers may notice that s is now in an uninitialized state. What happens on line 4 when we assign s to u?
The answer is: the code fails to compile:

Until we reinitialize s, the compiler will not allow us to use it.
From this example, we can see that assignment in Rust is cheap, while ownership remains clear.
If we don’t want to move ownership, we must explicitly call clone to copy the underlying data:
fn main() {
let s = vec!["udon".to_string(), "ramen".to_string(), "soba".to_string()];
let t = s.clone();
let u = s.clone();
}
Copy Types
As we’ve just seen, String, Vec, and similar types would incur significant cost if copied by default. Moving them keeps assignment cheap and ownership tracking clear. But for primitive types like integers, this special treatment isn’t necessary. Take i32 as an example:
- It’s just a few bits on the stack; copying is effectively free.
- Moving turns the original variable into an uninitialized state to prevent further use — but continuing to use an old integer value is not dangerous.
The benefits of move semantics don’t really apply to numbers and can even be inconvenient. For such types, Rust introduces the Copy trait (the one mentioned in the compile error earlier). For Copy types, what would normally be a move becomes a bitwise copy.
Only types that can be safely copied bit‑for‑bit may implement Copy: all primitive numeric types (integers and floats), bool, char, and tuples/arrays whose elements are all Copy.
Structs and enums are not Copy by default, but if all of their fields are Copy, you can derive it:
#[derive(Copy, Clone)]
struct Label { number: u32 }
If number were a String, this code would fail to compile because String is not Copy:
#[derive(Copy, Clone)]
struct Label { name: String }
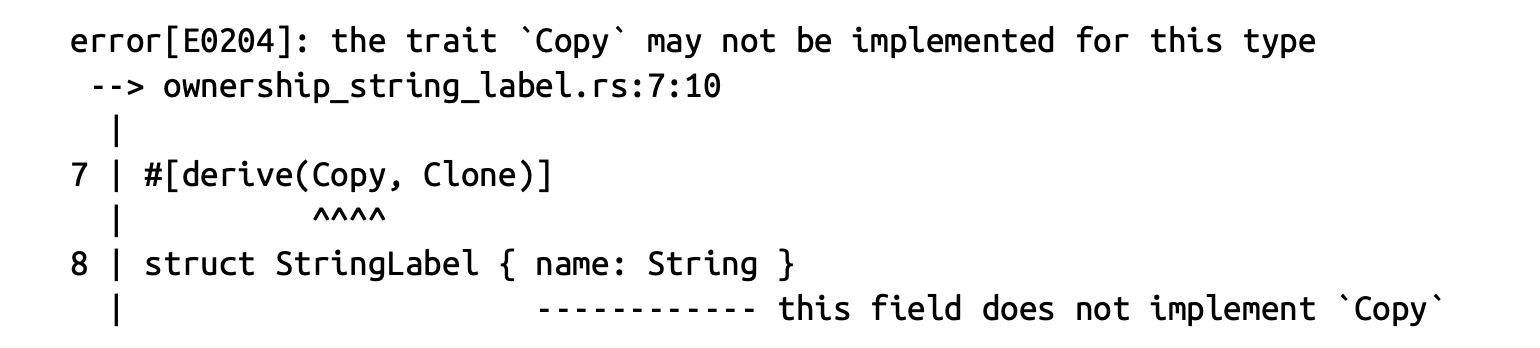
You might wonder if you can avoid using derive and hand‑write the implementation for Copy to bypass this restriction. The answer is no: the compiler will still reject it. Copy (full path std::marker::Copy) is a marker trait with no methods. It affects how the compiler generates code for assignments and other operations — whether it emits move or copy instructions — so its implementation is controlled by the compiler.
As we’ve seen, even when a type qualifies, it isn’t Copy by default. Rust does this because being Copy has very different implications for type implementors and consumers:
- For consumers,
Copyis convenient: using a value doesn’t invalidate the original. - For implementors,
Copyis restrictive: all fields must also beCopy, and if you later need to make the type non‑Copy, you must update all code that relies on it beingCopy.
Functions and Ownership
Passing a variable to a function has similar semantics to assigning it: it triggers a move or a copy.
fn main() {
let s = String::from("hello");
takes_ownership(s); // ownership of the string moves into takes_ownership
} // s goes out of scope here, but its value has already moved, so nothing happens
fn takes_ownership(some_string: String) {
println!("{}", some_string);
} // some_string goes out of scope here, and the string’s memory is freed
Likewise, returning a value from a function moves ownership to the caller:
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return value into s1
let s2 = String::from("hello");
let s3 = takes_and_gives_back(s2); // ownership of s2 moves into takes_and_gives_back, and its return value moves into s3
} // s1 and s3 go out of scope and free their memory; s2 has already moved, so nothing happens
fn gives_ownership() -> String {
let some_string = String::from("hello");
some_string // ownership of some_string moves out of gives_ownership
}
fn takes_and_gives_back(a_string: String) -> String {
a_string // ownership of a_string moves out of takes_and_gives_back
}
Suppose we want a function that computes the length of a string. With what we know so far, we might write:
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len();
(s, length)
}
Here, because we want to retain ownership of the argument, we have to return it alongside the computed length. We do this with a tuple, which quickly becomes clumsy. Fortunately, Rust has a better solution.
References
Rust has a kind of pointer called a reference that does not affect the lifetime of the value it points to. In fact, the compiler guarantees that a reference can never outlive the value it refers to.
In Rust, creating a reference to a value is called borrowing it. Borrowing lets you use a value without taking ownership.
References themselves are nothing new — they’re just addresses — but Rust’s rules for making them safe are quite innovative. The learning curve for this part can be steep, and in your early Rust days you’ll probably spend a lot of time fighting these compiler errors. But they pay off by preventing many classic, widespread bugs, and they shine even more in concurrent code.
With references, we can rewrite our string‑length function as:
fn calculate_length(s: &String) -> usize {
s.len()
}
This new version takes a reference to a String instead of taking ownership. The & indicates reference semantics.
Rust has two types of references:
- Shared references
&T: can be used to read through the reference only; these areCopy. - Mutable references
&mut T: can be used to read and write through the reference; these are notCopy.
The key rule is that at any given time you can either have one mutable reference or any number of shared references — in short, shared access is read‑only; mutable access is exclusive. This is analogous to a read–write lock. In fact, this rule also applies to the owner: when shared references exist, even the owner can only read, not mutate; when a mutable reference exists, the owner cannot be used at all.
Unlike C++, references in Rust must be explicitly created and explicitly dereferenced:
let x = 10;
let r = &x; // &x is a shared reference to x
assert!(*r == 10);
let mut y = 32;
let m = &mut y; // &mut y is a mutable reference to y
*m += 32; // explicit dereference
assert!(*m == 64);
Another rule is that Rust ensures references are always valid: unsafe references simply do not compile.
Here’s a simple example showing how Rust enforces this guarantee:
{
let r;
{
let x = 1;
r = &x;
}
assert_eq!(*r, 1);
}
This snippet fails to compile:

The error states that x lives only inside the inner block, but its reference is still used at the end of the outer block. That would be a dangling reference, and Rust rightfully rejects it.
This example shows that you cannot create a reference to a local variable and then use that reference outside the variable’s scope. Cases like this are easy for humans to spot, but they’re also a good way to understand how Rust does its checks.
Lifetimes
Rust tries to assign a lifetime to every reference that satisfies all constraints. A lifetime describes the scope within which a reference is valid. It exists only at compile time to help the compiler ensure memory safety. At runtime, a reference is just an address.
We’ve already seen one obvious constraint: a reference to x cannot outlive x itself. In other words, x’s lifetime must be at least as long as the reference’s lifetime:

This constraint sets an upper bound: the reference cannot outlive the value it points to.
Another constraint is that if we store a reference in variable r, the reference must remain valid for the entire lifetime of r (from its initialization to its last use). In other words, the reference’s lifetime must be at least as long as r’s lifetime:

This constraint sets a lower bound: the reference must remain valid for as long as it is used.
In our example, there is no lifetime that satisfies both constraints:

The same rules naturally apply when you take a reference to part of a larger data structure:
let v = vec![1, 2, 3];
let r = &v[1];
Here, the lifetime of v must be at least as long as that of &v[1], and the lifetime of r must be no longer than that of &v[1]. Similarly, if you create a vector of references, the vector’s lifetime must be no longer than the lifetimes of all the references it contains.
Calling functions and building new data structures introduce more constraints, but the borrow checker still essentially does the same thing: find lifetimes that satisfy all constraints. This is similar to what experienced C/C++ programmers mentally do while writing code, with the big difference that Rust understands and enforces these rules automatically.
Lifetime Parameters
Let’s look at another example. Suppose we want to write a function that returns the longer of two string slices. With what we know so far, we might write:
fn main() {
let string1 = "abcd";
let string2 = "xyz";
let result = longest(string1, string2);
println!("The longest string is {}", result);
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
Unfortunately, this doesn’t compile:

The compiler’s help message explains the problem: we need to add a lifetime parameter to the return type, because Rust cannot tell whether the returned reference points to x or to y. Even humans can’t say for sure by just looking at the signature — which branch runs depends on runtime data. The borrow checker doesn’t know the relationship between the lifetimes of x, y, and the return value, so it cannot prove that the return value is always valid.
To fix this, we must do what the compiler suggests and add lifetime parameters to express how the input and output lifetimes relate to each other:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
// ...
}
The syntax &'a marks a reference with a lifetime parameter. Lifetime parameters must start with ', and by convention we use lowercase letters to distinguish them from regular generic type parameters, for example:
&i32 // a shared reference
&'a i32 // a shared reference with an explicit lifetime
&'a mut i32 // a mutable reference with an explicit lifetime
Conceptually, a lifetime parameter is just another kind of generic parameter. Like lifetimes themselves, lifetime parameters exist only at compile time and have no runtime cost. They also do not change the actual lifetimes of variables or references.
This function signature now says: the function takes references with some lifetime 'a and returns a reference with the same lifetime 'a. That is, the returned reference must live at least as long as both the call and the returned value’s usage.
Since 'a is abstract, Rust can instantiate it as the shorter of the two argument lifetimes. In other words, x and y don’t need to have exactly the same lifetime.
With lifetime parameters, we can pass references with different lifetimes and let Rust catch potential bugs. For example:
fn main() {
let string1 = String::from("long string is long");
{
let string2 = String::from("xyz");
let result = longest(string1.as_str(), string2.as_str());
println!("The longest string is {}", result);
}
}
Here, string1 lives until the end of the outer scope, string2 lives only inside the inner scope, and result references something that remains valid until the end of the inner scope. The borrow checker accepts this code; it compiles and runs, printing The longest string is long string is long.
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {}", result);
}
If we try to compile this version, we get an error:
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {}", result);
| ------ borrow later used here
The error tells us that for result to be valid in println!, string2 would need to live until the end of the outer scope. Rust knows this because both parameters and the return value of longest share the same lifetime parameter 'a.
From a human’s perspective, we might reason that since string1 is longer, result will always point to string1. And since string1 is still valid in println!, why not allow it? However, what we’ve told Rust with the lifetime parameter is simply that the return value’s lifetime is tied to both arguments, and the compiler conservatively picks the shorter one. Given that string2 doesn’t live long enough, returning a reference tied to it would be unsafe, so Rust rejects the whole construct.
Fundamentally, lifetime parameters let us relate the lifetimes of multiple references in a function signature. Once these relationships are explicit, Rust has enough information to guarantee memory safety and to reject code that could produce dangling references or otherwise violate safety.
These examples also show that lifetime parameters appear only in function signatures. The function body and call sites generally don’t need additional annotations; the compiler can infer them.
Lifetime Elision
Since lifetimes exist to ensure the validity of references, every reference technically has a lifetime, and every function that takes references must conceptually have lifetime parameters.
In the early days of Rust, every reference had to have an explicit lifetime. But after writing a lot of Rust code, the language team noticed that in many situations programmers were writing the same lifetime annotations over and over again. These patterns were predictable and unambiguous, so they decided to bake them into the language. In those cases, the borrow checker can infer lifetimes without explicit annotations.
These built‑in patterns are called the lifetime elision rules:
- Each parameter that is a reference gets its own distinct lifetime parameter.
- If there is exactly one input lifetime parameter, that lifetime is assigned to all output lifetimes.
- If there are multiple input lifetime parameters, but one of them is
&selfor&mut self, the lifetime ofselfis assigned to all output lifetimes.
Structs and Lifetime Parameters
Lifetimes don’t magically disappear just because references are stored in structs. When we store references inside a struct, every reference field must have a lifetime parameter:
struct ImportantExcerpt<'a> {
part: &'a str,
}
This struct has a single field part, a string slice. The lifetime parameter says that an ImportantExcerpt instance cannot outlive the string slice that part points to.
The 'static Lifetime
Rust also has a special lifetime 'static, which means “for the entire duration of the program.”
All string literals have this lifetime, because their text is baked directly into the program’s binary. So the full type of a string literal looks like this:
let s: &'static str = "I have a static lifetime.";
You might have seen compiler suggestions mentioning 'static. Before using it, think carefully about whether the reference you hold truly remains valid for the entire program. Even if it does, consider whether it needs to live that long. In most cases, the real problem is an attempted dangling reference or mismatched lifetimes. You should fix those issues instead of slapping 'static on and hoping it compiles.
Conclusion
In this article we’ve discussed several key Rust concepts:
- Ownership and moves pair allocation and deallocation one‑to‑one.
- References add flexibility to ownership.
- Lifetimes guarantee the safety of references.
Since garbage‑collected languages became popular in the 90s, if you rely on GC and don’t pay attention to design, your program structure often ends up like this — a “sea of objects”:
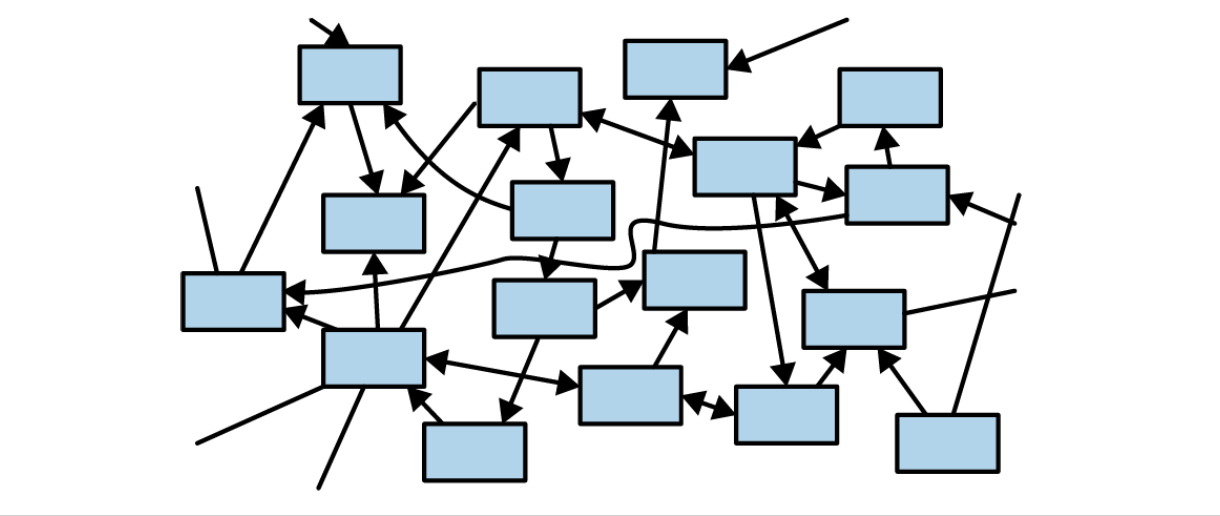
This approach has its pros and cons: you can write code quickly, but tangled dependencies blur boundaries and make testing difficult.
Rust, on the other hand, gives us a weapon for taking arms against a sea of objects, encouraging designs more like this — with simple relationships and clear boundaries:
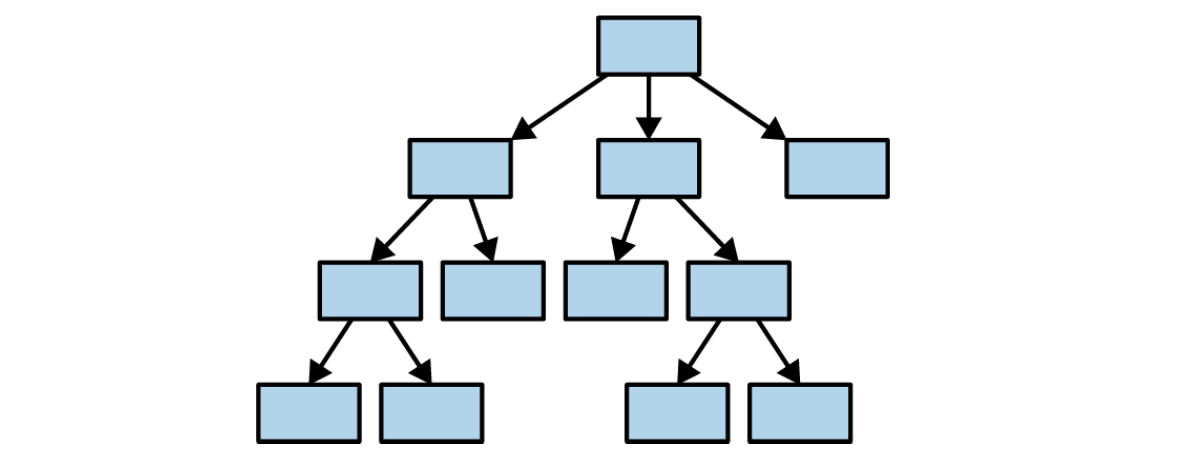
Rust’s philosophy is to move the pain of maintaining a program from the future into the present. Remarkably, this works very well. Rust forces you to understand why your program is memory‑safe, and even thread‑safe, and it nudges you to think more carefully about architecture and design.